
هوش مصنوعی GPT 5.2 جدیدترین و پیشرفتهترین مدل زبانی ارائهشده تا امروز است که با تمرکز ویژه بر کارهای حرفهای، پروژههای پیچیده و long-running agents (ایجنتهایی که قادرند وظایف و پروژههای چندمرحلهای را در بازههای زمانی طولانی با حفظ هدف و کانتکست مدیریت کنند) طراحی شده است. این مدل نسل جدیدی از هوش مصنوعی را معرفی میکند که نهتنها در پاسخگویی متنی، بلکه در انجام وظایفی مانند ساخت فایلهای اکسل، طراحی ارائههای حرفهای، کدنویسی پیشرفته، تحلیل تصاویر، درک کانتکستهای بسیار طولانی و مدیریت پروژههای چندمرحلهای عملکردی فراتر از انتظار دارد.
بر اساس گزارش کاربران سازمانی، استفاده از مدلهای GPT تاکنون روزانه بین ۴۰ تا ۶۰ دقیقه در زمان کاری صرفهجویی ایجاد کرده و کاربران حرفهای حتی بیش از ۱۰ ساعت در هفته زمان آزاد به دست آوردهاند. هوش مصنوعی GPT 5.2 با هدف افزایش هرچه بیشتر بهرهوری و خلق ارزش اقتصادی بالاتر توسعه یافته و در بنچمارکهای معتبری مانند GDPval توانسته در انجام وظایف تخصصی، حتی از متخصصان انسانی در دهها حوزه شغلی پیشی بگیرد.
در این مقاله، به بررسی کامل GPT 5.2، قابلیتها، کاربردها و همچنین نحوه نصب و دانلود آن میپردازیم تا ببینیم چرا این مدل را میتوان یکی از مهمترین جهشهای تاریخ هوش مصنوعی دانست.
فهرست عنوان های مقاله
جدیدترین ویژگیهای GPT 5.2:
- هوش و استدلال قویتر در وظایف چندمرحلهای و مسائل پیچیده
- هوش مصنوعی GPT 5.2 پیشرفتهترین مدل زبانی برای کارهای حرفهای است.
- افزایش محسوس بهرهوری و صرفهجویی قابلتوجه در زمان کاری.
- پشتیبانی بیسابقه از کانتکست طولانی (تا صدها هزار توکن)
- کاهش محسوس خطا و هالوسینیشن در پاسخهای تحلیلی و حرفهای
- Tool Calling پیشرفتهتر برای اجرای کامل گردشکارهای چندمرحلهای
- درک تصویری دقیقتر (نمودارها، داشبوردها، UI و دیاگرامها)
- عملکرد پیشرو در برنامهنویسی (دیباگ، ریفکتور، فرانتاند و UI پیچیده)
- تولید اکسل و پرزنتیشن در سطح سازمانی
- توانمندی بالا در علم و ریاضیات پیشرفته
- استدلال انتزاعی قویتر (ARC-AGI)
- ایمنی و پاسخدهی مسئولانهتر در مکالمات حساس
- بهرهوری توکنی بالاتر و هزینه کمتر برای رسیدن به کیفیت مطلوب
- سه نسخه متناسب با نیاز کاربر: Instant (سریع)، Thinking (عمیق)، Pro (حداکثر کیفیت)
عملکرد GPT 5.1 در بنچمارک ها و آزمون های تخصصی
هوش مصنوعی GPT 5.2 با ثبت رکوردهای جدید در بسیاری از بنچمارکهای معتبر جهانی، استاندارد تازهای در ارزیابی مدلهای زبانی پیشرفته ایجاد کرده است. این مدل در آزمونهایی که مهارتهای واقعی موردنیاز بازار کار، تحلیل علمی، استدلال انتزاعی و حل مسائل پیچیده را میسنجند، عملکردی فراتر از مدلهای قبلی و حتی متخصصان انسانی نشان داده است.
در بنچمارک GDPval که وظایف دانشی دقیق را در ۴۴ شغل مختلف بررسی میکند، GPT 5.2 توانسته در بیش از ۷۰٪ موارد برنده شود یا حداقل به عملکرد انسانی برسد؛ جهشی قابلتوجه نسبت به نسل قبل. همچنین در حوزههایی مانند مهندسی نرمافزار، ریاضیات پیشرفته، علوم و استدلال انتزاعی، پیشرفتهای چشمگیری ثبت کرده است.
مقایسه عملکرد GPT 5.2 با نسل قبلی
| بنچمارک | حوزه ارزیابی | GPT-5.2 Thinking | GPT-5.1 / GPT-5 |
|---|---|---|---|
| GDPval | وظایف دانشی (۴۴ شغل) | 70.9٪ | 38.8٪ |
| SWE-Bench Pro | مهندسی نرمافزار | 55.6٪ | 50.8٪ |
| SWE-Bench Verified | مهندسی نرمافزار | 80.0٪ | 76.3٪ |
| (no tools) GPQA Diamond | سؤالات علمی | 92.4٪ | 88.1٪ |
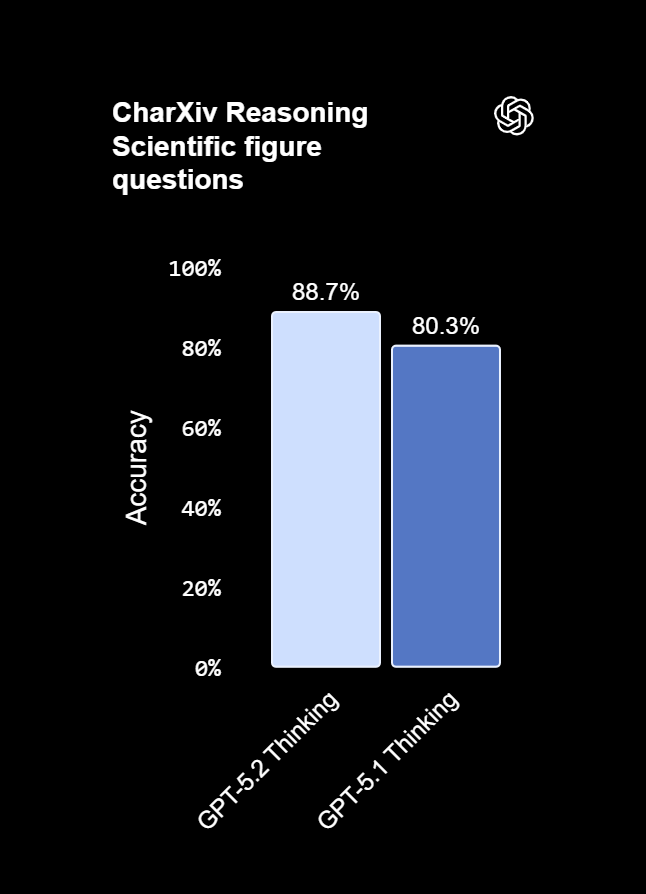
| (w/ Python) CharXiv Reasoning | تحلیل نمودارهای علمی | 88.7٪ | 80.3٪ |
| (no tools) AIME 2025 | ریاضیات رقابتی | 100٪ | 94.0٪ |
| FrontierMath (Tier 1–3) | ریاضیات پیشرفته | 40.3٪ | 31.0٪ |
| FrontierMath (Tier 4) | ریاضیات بسیار پیشرفته | 14.6٪ | 12.5٪ |
| ARC-AGI-1 | استدلال انتزاعی | 86.2٪ | 72.8٪ |
| ARC-AGI-2 | استدلال انتزاعی | 52.9٪ | 17.6٪ |
شرکتها و پلتفرمهای بزرگی مانند Notion، Shopify، Zoom و Box گزارش دادهاند که GPT 5.2 در استدلال بلندمدت (Long-Horizon Reasoning) و استفاده هوشمند از ابزارها عملکردی در سطح پیشرفتهترین مدلهای موجود دارد.
همچنین سازمانهایی مانند Databricks و Hex این مدل را در تحلیل داده، کارهای ایجنتمحور و بررسی اسناد بسیار کارآمد دانستهاند. در حوزه برنامهنویسی نیز شرکتهایی نظیر JetBrains و Warp تأکید کردهاند که GPT 5.2 بهبود محسوسی در کدنویسی تعاملی، کدریویو و باگیابی ایجاد کرده است.
در مجموع، هوش مصنوعی GPT 5.2 با بهبود چشمگیر در هوش عمومی، درک کانتکستهای طولانی، تعامل با ابزارها و پردازش تصویر، به قدرتمندترین مدل برای اجرای پروژههای پیچیده و واقعی از ابتدا تا انتها تبدیل شده است.
عملکرد مدل GPT 5.2
انجام وظایف با ارزش اقتصادی (Economically Valuable Tasks)
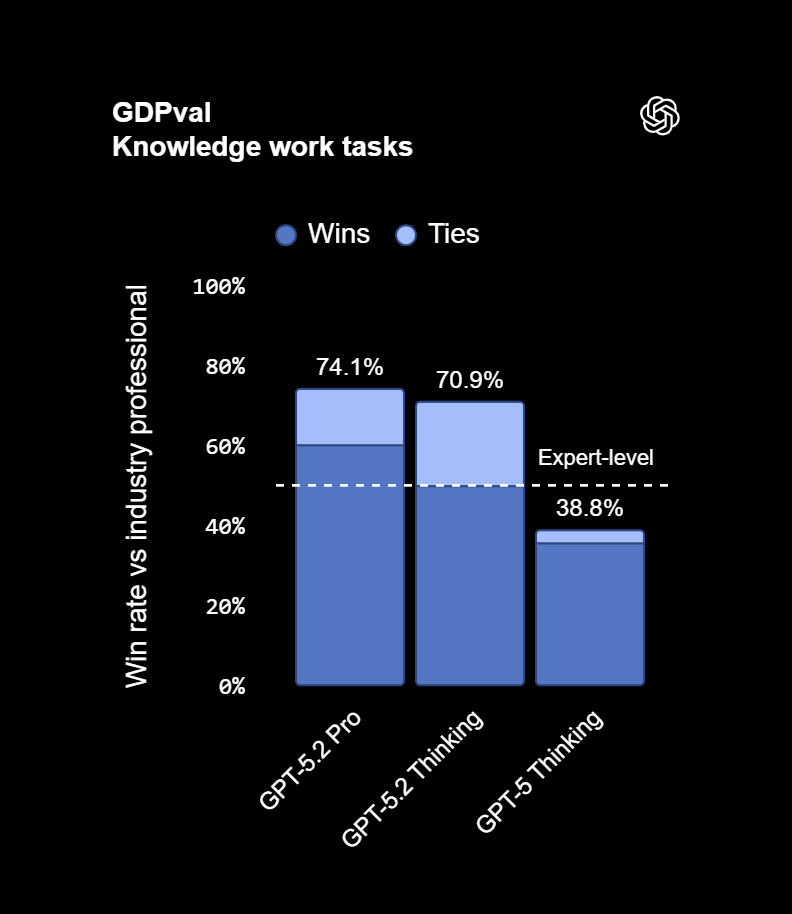
هوش مصنوعی GPT 5.2 Thinking قدرتمندترین مدل تاکنون برای استفادههای واقعی و حرفهای محسوب میشود. این مدل در ارزیابی GDPval که وظایف دانشی دقیق را در ۴۴ شغل مختلف از مهمترین صنایع اقتصادی بررسی میکند، به رکوردی دست یافته که آن را برای اولین بار به سطح عملکرد متخصصان انسانی میرساند.
بر اساس قضاوت داوران انسانی متخصص، GPT 5.2 Thinking در ۷۰.۹٪ از مقایسهها توانسته عملکردی برابر یا بهتر از متخصصان صنعتی ارائه دهد. این وظایف شامل تولید خروجیهای واقعی مانند پرزنتیشنهای فروش، فایلهای اکسل حسابداری، برنامهریزی نیروی انسانی، نمودارهای تولید و محتوای ویدیویی کوتاه بودهاند
خلاصه نتایج GDPval
| مدل | نرخ برد یا مساوی در برابر متخصص انسانی |
|---|---|
| GPT-5.2 Pro | 74.1٪ |
| GPT-5.2 Thinking | 70.9٪ |
| GPT-5 Thinking | 38.8٪ |
نکته مهم این است که GPT 5.2 Thinking توانسته این خروجیها را با بیش از ۱۱ برابر سرعت بالاتر و کمتر از ۱٪ هزینه نیروی انسانی متخصص تولید کند؛ موضوعی که نشان میدهد در کنار نظارت انسانی، این مدل میتواند نقش بسیار مؤثری در کارهای حرفهای ایفا کند.
یکی از داوران GDPval درباره خروجیهای GPT 5.2 گفته است:
«این یک جهش کاملاً محسوس در کیفیت خروجی است؛ بهگونهای که به نظر میرسد توسط یک شرکت حرفهای با تیم متخصص تولید شده باشد.»
علاوه بر این، در بنچمارک داخلی مرتبط با مدلسازی مالی تحلیلگران جونیور بانکداری سرمایهگذاری (مانند ساخت مدل سهصورت مالی یا LBO برای شرکتهای Fortune 500)، عملکرد GPT 5.2 Thinking بهطور میانگین ۹.۳٪ بهتر از GPT-5.1 بوده و امتیاز آن از ۵۹.۱٪ به ۶۸.۴٪ افزایش یافته است.
مقایسههای مستقیم نیز نشان میدهد که GPT 5.2 Thinking در ساخت اکسلها و اسلایدها از نظر:
- دقت محاسبات
- ساختاردهی دادهها
- فرمتبندی حرفهای
- و سطح جزئیات
بهطور محسوسی پیشرفتهتر از نسلهای قبلی عمل میکند.
برای استفاده از قابلیتهای جدید ساخت اسپردشیت و پرزنتیشن در ChatGPT، لازم است از پلنهای Plus، Pro، Business یا Enterprise استفاده کرده و مدل GPT-5.2 Thinking یا Pro را انتخاب کنید. تولید خروجیهای پیچیده ممکن است چند دقیقه زمان ببرد.
نمونهٔ مقایسهای خروجیهای اسپریدشیت از GPT-5.1 در مقابل GPT-5.2 (GPT-5.1 سمت چپ و GPT-5.2 تصویر راست)
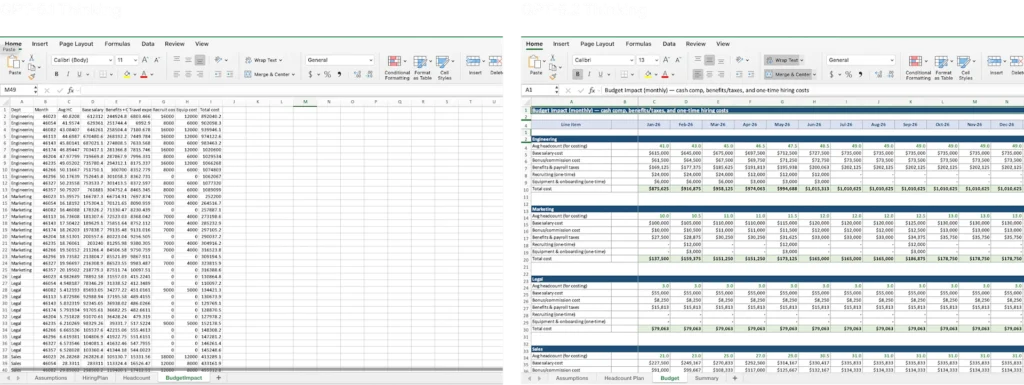
یک مدل برنامهریزی نیروی کار ایجاد کن: تعداد کارکنان فعلی (Headcount)، برنامه استخدام، نرخ ریزش نیرو (Attrition)، و تأثیر بودجه.
بخشهای مهندسی، بازاریابی، حقوقی و فروش را هم شامل شود.
نمونهٔ مقایسهای ساخت اسلاید پاورپوینت از GPT-5.1 در مقابل GPT-5.2 (GPT-5.1 سمت چپ و GPT-5.2 تصویر راست)

Coding (عملکرد GPT 5.2 در برنامهنویسی)
هوش مصنوعی GPT 5.2 Thinking در حوزه برنامهنویسی و مهندسی نرمافزار، به یک سطح جدید از عملکرد رسیده و رکورد تازهای را در بنچمارک معتبر SWE-Bench Pro ثبت کرده است. این بنچمارک یکی از سختگیرانهترین آزمونهای مهندسی نرمافزار در دنیای واقعی محسوب میشود و وظایفی را ارزیابی میکند که مستقیماً از پروژهها و کدبیسهای واقعی صنعتی گرفته شدهاند. در SWE-Bench Pro، مدل GPT 5.2 Thinking به دقت ۵۵.۶٪ دست یافته که بالاترین نتیجه ثبتشده تاکنون است. برخلاف نسخه SWE-Bench Verified که تنها زبان پایتون را پوشش میدهد، نسخه Pro چهار زبان برنامهنویسی مختلف را ارزیابی کرده و با هدف کاهش آلودگی داده، افزایش تنوع و نزدیک شدن به شرایط واقعی صنعت طراحی شده است.
در این آزمون، مدل باید:
- یک ریپازیتوری واقعی را تحلیل کند
- مشکل یا تسک مهندسی نرمافزار را درک کند
- و یک Patch کامل و قابل اجرا برای رفع مشکل ارائه دهد
علاوه بر این، GPT 5.2 Thinking در نسخه SWE-Bench Verified نیز به امتیاز ۸۰٪ دست یافته که بالاترین رکورد ثبتشده در این ارزیابی است.

کاربرد عملی در دنیای واقعی
این پیشرفتها در عمل به معنای آن است که هوش مصنوعی GPT 5.2 میتواند:
- دیباگ کدهای Production را با دقت بالاتری انجام دهد
- فیچرهای جدید را در پروژههای واقعی پیادهسازی کند
- کدبیسهای بزرگ را ریفکتور کند
- و اصلاحات نرمافزاری را از ابتدا تا انتها با نیاز کمتر به مداخله انسانی انجام دهد
بهبود چشمگیر در Front-end و UI
تستکنندگان اولیه گزارش دادهاند که GPT 5.2 Thinking در توسعه فرانتاند نیز بهطور محسوسی قویتر از GPT-5.1 عمل میکند. این مدل بهویژه در:
- طراحی رابطهای کاربری پیچیده
- پیادهسازی UIهای غیرمتعارف
- و کار با المانهای سهبعدی (3D)
عملکرد بسیار بهتری دارد و میتواند بهعنوان یک همکار روزانه قدرتمند برای برنامهنویسان Front-end و Full-stack مورد استفاده قرار گیرد.
دقت و واقعیتسنجی (Factuality) در GPT 5.2
یکی از مهمترین بهبودهای هوش مصنوعی GPT 5.2 Thinking نسبت به نسل قبل، کاهش خطا و «توهمزایی» (Hallucination) است. طبق ارزیابی انجامشده روی مجموعهای از پرسشهای ناشناسسازیشده (de-identified) از کاربران ChatGPT، پاسخهایی که دارای خطا بودند در GPT 5.2 Thinking حدود ۳۰٪ کمتر از GPT-5.1 Thinking گزارش شدهاند.
این موضوع برای کاربران حرفهای یک مزیت بسیار مهم دارد: وقتی از مدل برای تحقیق، نگارش محتوا، تحلیل داده، و پشتیبانی تصمیمگیری استفاده میکنید، احتمال اشتباهات کمتر میشود و خروجیها قابلاعتمادتر خواهند بود؛ یعنی مدل برای «کار روزمره دانشی» (Everyday Knowledge Work) پایدارتر و مطمئنتر عمل میکند.
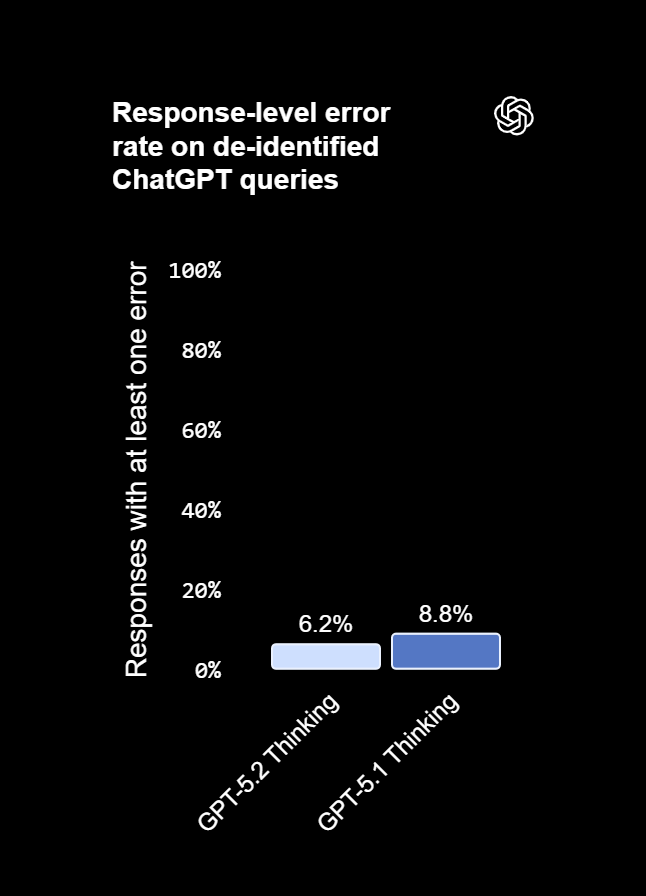
نکته مهم: در این آزمایش، میزان تلاش استدلال (Reasoning effort) روی حداکثر تنظیم شده و ابزار جستجو نیز فعال بوده است. همچنین تشخیص خطاها توسط مدلهای دیگر انجام شده که خودِ آنها هم ممکن است خطا داشته باشند. علاوه بر این، نرخ خطا در سطح «پاسخ کامل» معمولاً بالاتر از نرخ خطا در سطح «ادعا» است؛ چون هر پاسخ میتواند شامل چندین ادعای جداگانه باشد.
با این حال، مثل هر مدل دیگری، GPT 5.2 Thinking بینقص نیست و در موضوعات حساس یا حیاتی، همچنان باید پاسخها را حتماً راستیآزمایی و دوبارهچک کرد.
کانتکست طولانی (Long Context) در GPT 5.2
هوش مصنوعی GPT 5.2 Thinking در زمینه درک و استدلال روی کانتکستهای بسیار طولانی، به یک رکورد جدید دست یافته است. این مدل در ارزیابی OpenAI MRCRv2 که توانایی یک مدل در ترکیب اطلاعات پراکنده در اسناد طولانی را میسنجد، بهترین عملکرد ثبتشده تاکنون را ارائه کرده است.
در وظایف واقعی مانند تحلیل عمیق اسناد که نیازمند ارتباط دادن اطلاعات در میان صدها هزار توکن هستند، GPT 5.2 Thinking بهطور محسوسی دقیقتر از GPT-5.1 Thinking عمل میکند. بهویژه، این مدل اولین مدلی است که در نسخه 4-needle از آزمون MRCR (با طول کانتکست تا ۲۵۶ هزار توکن) به دقتی نزدیک به ۱۰۰٪ دست یافته است.
از نظر کاربرد عملی، این پیشرفت به متخصصان امکان میدهد تا از هوش مصنوعی GPT 5.2 برای کار با اسناد بسیار حجیم مانند:
- گزارشهای طولانی
- قراردادهای حقوقی
- مقالات و پژوهشهای علمی
- متن جلسات و مصاحبهها (Transcripts)
- پروژههای چندفایلی و چندمنبعی
استفاده کنند، بدون اینکه انسجام، دقت یا ارتباط مفهومی در طول متن از بین برود. این ویژگی، GPT 5.2 را به گزینهای ایدهآل برای تحلیل عمیق، ترکیب اطلاعات از منابع متعدد و گردشکارهای پیچیده حرفهای تبدیل میکند.
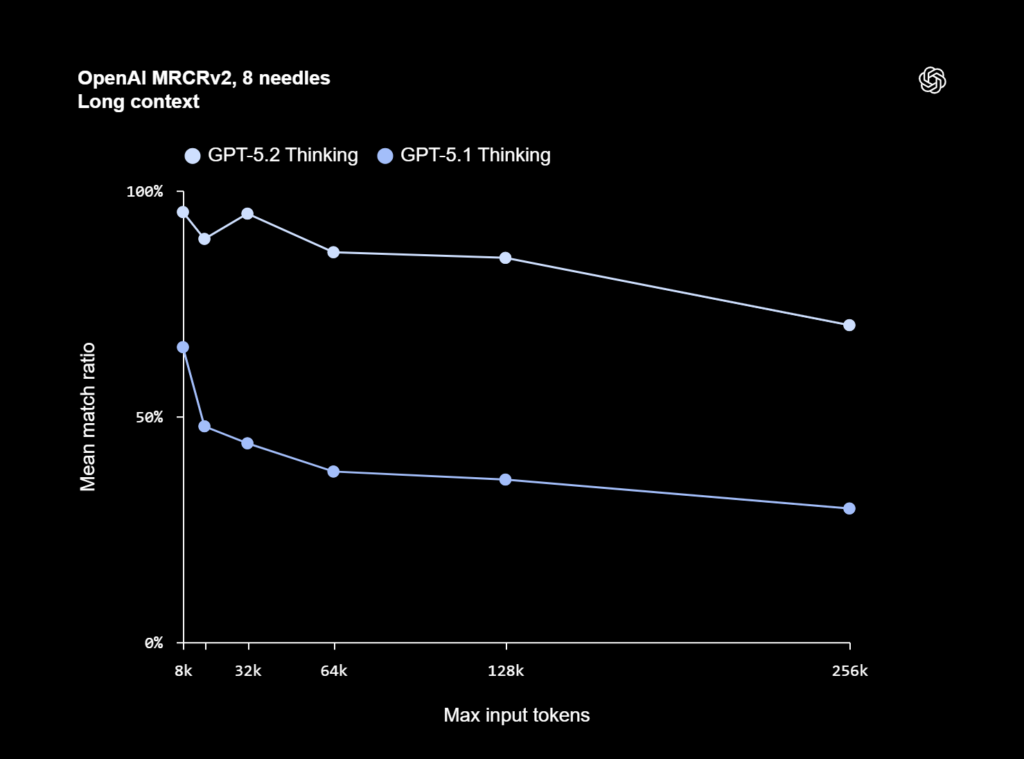
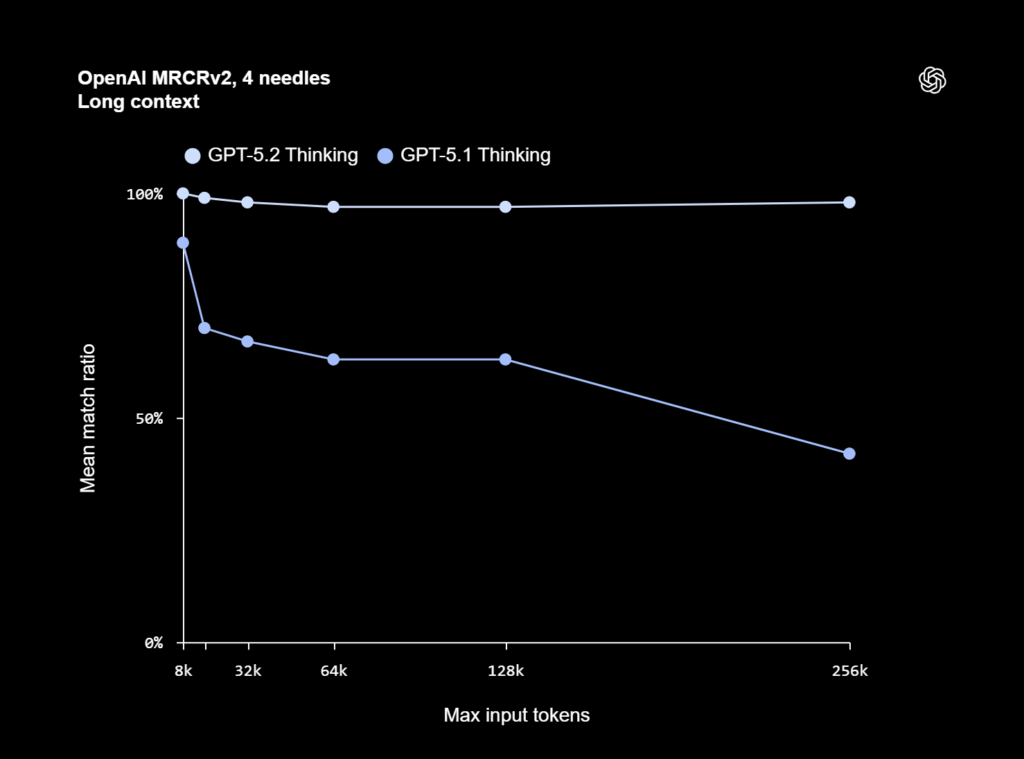
OpenAI-MRCR v2 یک نوع تست است که بررسی میکند آیا مدل هوش مصنوعی میتواند در میان یک متن بسیار طولانی (haystacks) یک درخواست خاص کاربر (سوزن) را پیدا کرده و پاسخ درست همان درخواست را بازتولید کند.
در نسخهٔ جدید این آزمون، برخی خطاهای نسخهٔ قبلی اصلاح شده و دقت اندازهگیری بهتر شده است.
شاخصی به نام Mean Match Ratio هم نشان میدهد پاسخ مدل چقدر با پاسخ صحیح تطابق متنی دارد.
در نمودارها نیز ورودیهای خیلی بزرگ (مثلاً 256 هزار توکن) بررسی شده تا مشخص شود مدل هنگام پردازش متنهای عظیم چقدر عملکرد خود را حفظ میکند.
بینایی ماشین (Vision) در GPT 5.2
هوش مصنوعی GPT 5.2 Thinking قویترین مدل بینایی ارائهشده تا امروز است و درک تصویری را به سطح جدیدی رسانده است. طبق ارزیابیها، این مدل توانسته نرخ خطا را در تحلیل نمودارها و درک رابطهای نرمافزاری تقریباً به نصف کاهش دهد؛ پیشرفتی قابلتوجه نسبت به نسلهای قبلی.
در کاربردهای حرفهای روزمره، این بهبود به این معناست که GPT 5.2 میتواند تصاویر مختلف را با دقت بسیار بالاتری تفسیر کند، از جمله:
- داشبوردهای تحلیلی و مدیریتی
- اسکرینشات محصولات و نرمافزارها
- دیاگرامهای فنی و مهندسی
- گزارشهای بصری و نموداری
این قابلیت بهویژه در حوزههایی مانند مالی، عملیات، مهندسی، طراحی و پشتیبانی مشتری که اطلاعات بصری نقش کلیدی دارند، ارزش بالایی ایجاد میکند. در نتیجه، هوش مصنوعی GPT 5.2 نهتنها متن، بلکه دادههای بصری را نیز بهصورت دقیق و قابلاعتماد در فرآیندهای تصمیمگیری و کاری تحلیل میکند.
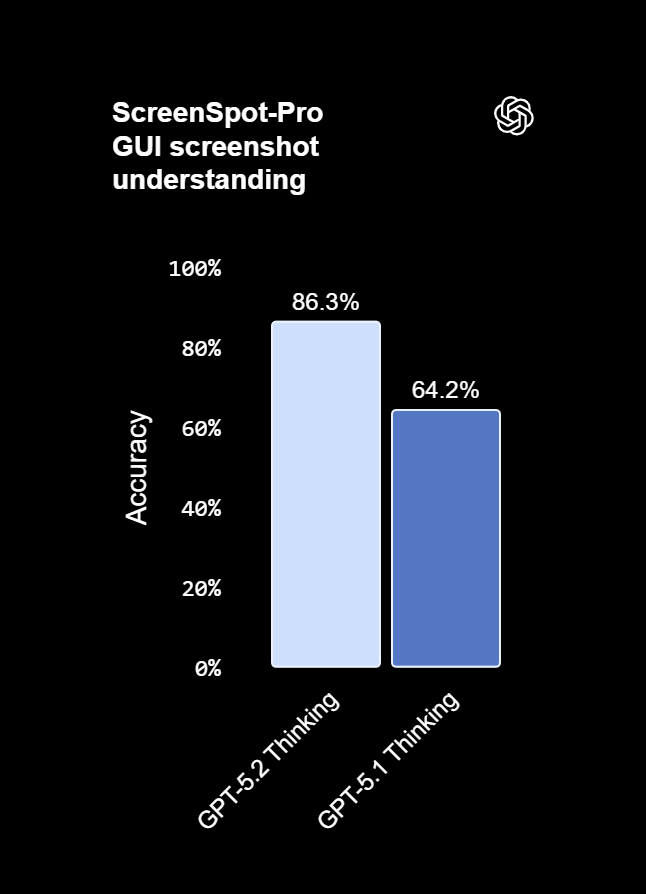
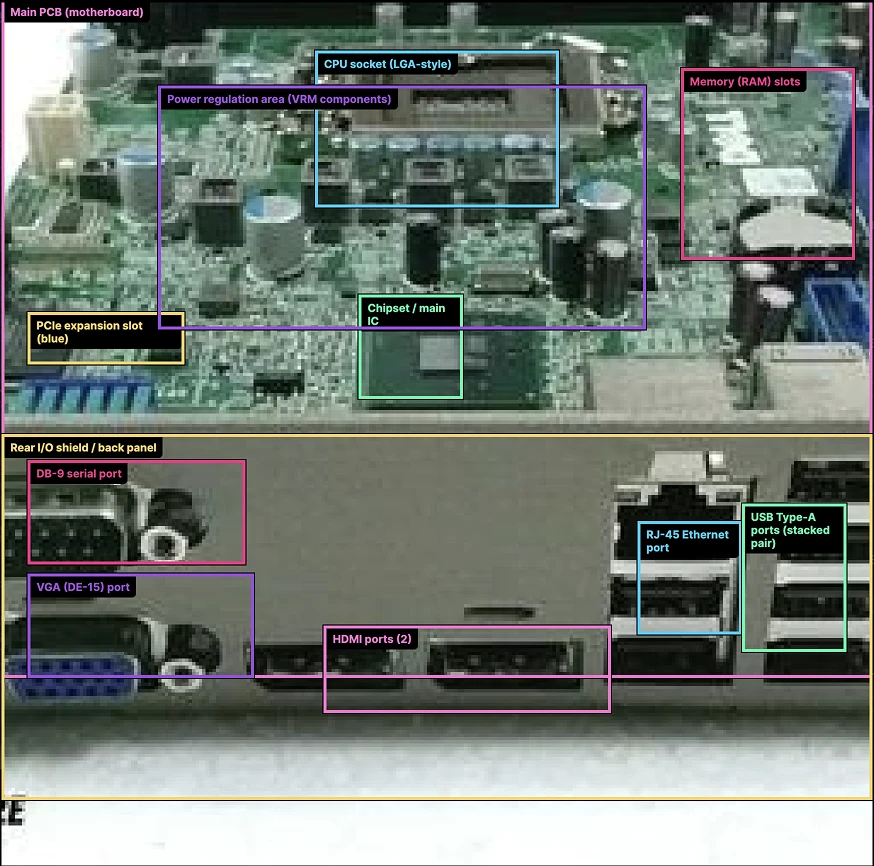
درک بهتر چیدمان و موقعیت عناصر تصویری در GPT 5.2
در مقایسه با مدلهای قبلی، هوش مصنوعی GPT 5.2 Thinking درک بسیار قویتری از موقعیت نسبی عناصر داخل تصویر دارد؛ قابلیتی که در مسائلی که چیدمان فضایی نقش کلیدی در حل آنها دارد، اهمیت زیادی پیدا میکند. در یک نمونه آزمایشی، از مدل خواسته شده تا اجزای موجود در یک تصویر (برای مثال، یک مادربرد) را شناسایی کرده و برای هر بخش، برچسب همراه با محدوده تقریبی (Bounding Box) ارائه دهد. حتی در تصاویری با کیفیت پایین، GPT 5.2 Thinking توانسته بخشهای اصلی تصویر را بهدرستی تشخیص داده و در بسیاری از موارد، محل جعبهها را نزدیک به موقعیت واقعی اجزا قرار دهد.در مقابل، GPT-5.1 تنها تعداد محدودی از اجزا را شناسایی کرده و درک ضعیفتری از چیدمان فضایی و ارتباط اجزای تصویر با یکدیگر نشان داده است. البته هر دو مدل همچنان دچار خطاهایی میشوند، اما مقایسهها نشان میدهد که GPT 5.2 در مجموع فهم عمیقتر و دقیقتری از تصویر ارائه میدهد؛ ویژگیای که آن را برای کاربردهای فنی، آموزشی و تحلیلی مبتنی بر تصویر بسیار مناسبتر میکند.

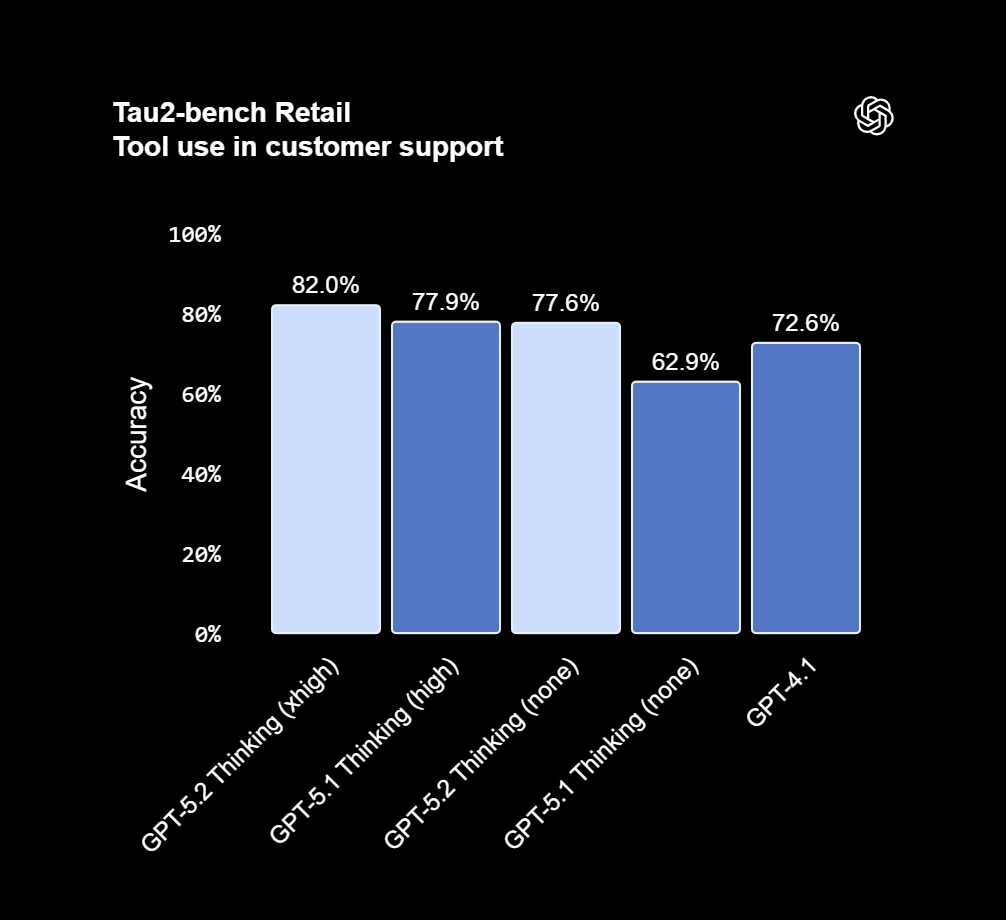
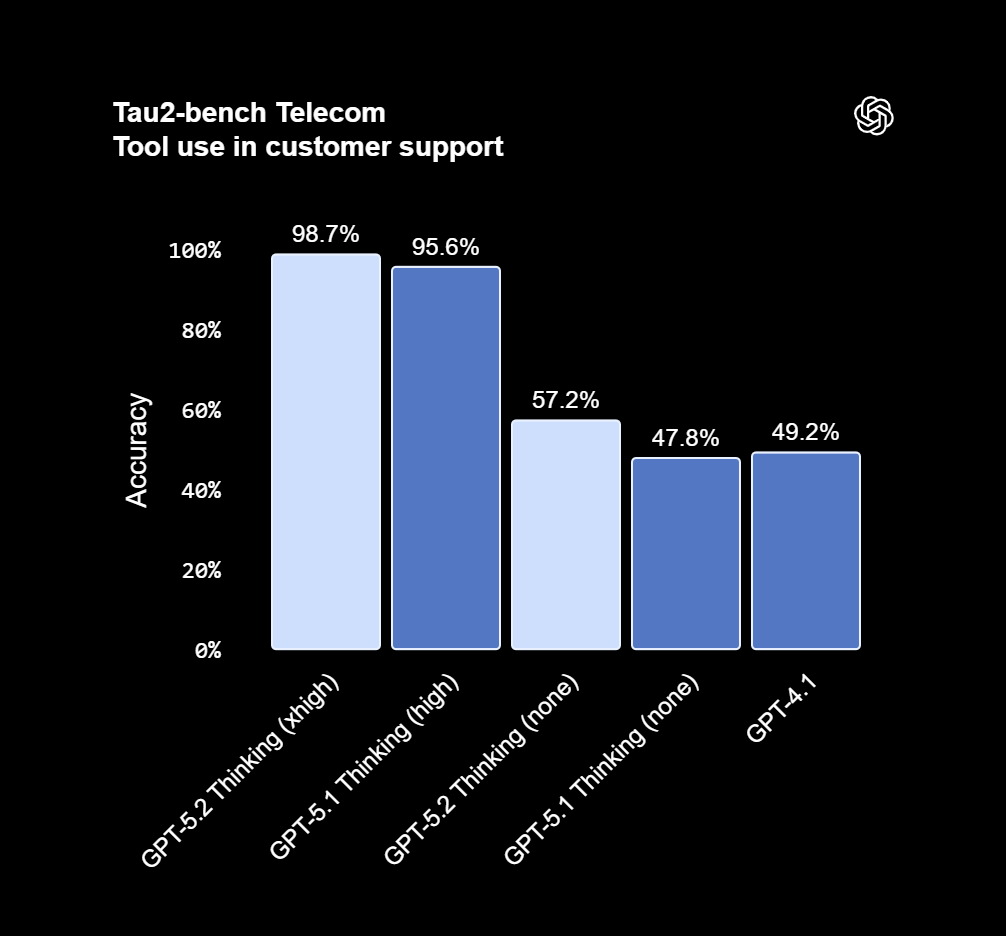
فراخوانی ابزار (Tool Calling)
یکی از مهمترین جهشهای هوش مصنوعی GPT 5.2 Thinking توانایی آن در استفاده دقیق و قابلاعتماد از ابزارها در پروژههای طولانی و چندمرحلهای است. این مدل در بنچمارک Tau2-bench Telecom به امتیاز ۹۸.۷٪ رسیده و رکورد جدیدی ثبت کرده است؛ عددی که نشان میدهد GPT 5.2 میتواند در مکالمههای چندمرحلهای (Multi-turn) و کارهای طولانی، ابزارها را با ثبات بسیار بالاتری فراخوانی و مدیریت کند.
نکته مهمتر این است که در سناریوهایی که سرعت پاسخ اهمیت بالایی دارد (Latency-sensitive)، GPT 5.2 حتی در حالت کاهش تلاش استدلال (reasoning.effort='none') هم عملکرد بهتری نسبت به GPT-5.1 و GPT-4.1 ارائه میدهد؛ یعنی هم سریعتر و هم کمخطاتر میتواند کارها را جلو ببرد.
نتیجه عملی برای کاربران حرفهای
این پیشرفت در دنیای واقعی یعنی اجرای گردشکارهای «سر تا ته» با کیفیت بالاتر، مثل:
- رسیدگی به کیسهای پشتیبانی مشتری
- دریافت اطلاعات از چند سیستم مختلف (CRM، دیتابیس، پنل سفارشها، تیکتینگ و …)
- اجرای تحلیلها و گزارشگیری
- تولید خروجی نهایی (گزارش، ایمیل، فرم، اکسل یا جمعبندی اجرایی)
با خرابی کمتر بین مراحل و نیاز کمتر به اصلاح دستی.
مثال واقعی از یک مسئله چندمرحلهای
در یک سناریوی پیچیده پشتیبانی مشتری، مسافری گزارش میدهد که:
- پروازش تأخیر داشته
- اتصال (Connection) را از دست داده
- مجبور به اقامت یکشبه در نیویورک شده
- و نیاز پزشکی به صندلی خاص (Special seating) دارد
در چنین وضعیتی، GPT 5.2 میتواند کل زنجیره اقدامات را هماهنگ کند؛ از جمله:
- رزرو مجدد پرواز (Rebooking)
- ثبت و پیگیری درخواست کمک ویژه و صندلی مناسب
- محاسبه و پیگیری جبران خسارت یا غرامت
و در نهایت، یک نتیجه کاملتر و اجراییتر نسبت به GPT-5.1 ارائه دهد؛ دقیقاً همان چیزی که در سیستمهای چندایجنتی و اتوماسیون سازمانی، تعیینکننده است.
علم و ریاضیات (Science & Math) در GPT 5.2
یکی از اهداف اصلی توسعه هوش مصنوعی، شتابدادن به پیشرفتهای علمی و ریاضی به نفع همه است. در همین راستا، GPT 5.2 با همکاری و بازخورد مستقیم پژوهشگران طراحی شده تا بتواند فرآیند تحقیق، تحلیل و حل مسائل پیچیده علمی را سریعتر و دقیقتر کند.
GPT-5.2 Pro و GPT-5.2 Thinking در حال حاضر بهعنوان قویترین مدلهای جهان برای کمک به پژوهشگران شناخته میشوند. این مدلها در بنچمارکهای سختگیرانه علمی و ریاضی، عملکردی در سطحی بیسابقه ارائه دادهاند.
عملکرد در سؤالات علمی (GPQA Diamond)
در بنچمارک GPQA Diamond که یک آزمون چندگزینهای در سطح تحصیلات تکمیلی (Graduate-level) و مقاوم در برابر جستجوی اینترنتی است، مدلهای GPT 5.2 نتایج زیر را ثبت کردهاند:
| مدل | دقت پاسخگویی |
|---|---|
| GPT-5.2 Pro | 93.2٪ |
| GPT-5.2 Thinking | 92.4٪ |
| GPT-5.1 Thinking | 88.1٪ |
این آزمون شامل سؤالات تخصصی در فیزیک، شیمی و زیستشناسی است و بدون استفاده از ابزار خارجی، با حداکثر توان استدلال اجرا شده است.
پیشرفت چشمگیر در ریاضیات پیشرفته (FrontierMath)
در ارزیابی FrontierMath (Tier 1–3) که مسائل ریاضی در سطح متخصصان را بررسی میکند، GPT 5.2 Thinking رکورد جدیدی ثبت کرده و توانسته ۴۰.۳٪ از مسائل را حل کند؛ جهشی قابلتوجه نسبت به GPT-5.1 که دقت ۳۱٪ داشته است.
در این آزمون:
- مسائل در سطح ریاضیات پیشرفته هستند
- ابزار پایتون فعال بوده
- و تلاش استدلال روی حداکثر تنظیم شده است
تأثیر واقعی در پژوهش علمی
نشانههای اولیه حاکی از آن است که مدلهای GPT 5.2 میتوانند بهصورت ملموس پیشرفت علم و ریاضیات را تسریع کنند. برای مثال، در یکی از همکاریهای اخیر با GPT-5.2 Pro، پژوهشگران روی یک سؤال باز در نظریه یادگیری آماری کار کردند. در یک چارچوب مشخص و محدود، مدل موفق شد یک ایده اثبات (Proof) پیشنهاد دهد که بعداً توسط نویسندگان مقاله بررسی، تأیید و با نظر متخصصان مستقل بازبینی شد.
این مثال نشان میدهد که مدلهای مرزی (Frontier Models) مانند GPT 5.2، در کنار نظارت دقیق انسانی، میتوانند به ابزار قدرتمندی برای کمک به پژوهشهای علمی و ریاضی پیشرفته تبدیل شوند؛ نه بهعنوان جایگزین دانشمند، بلکه بهعنوان یک شتابدهنده هوشمند تحقیق.
استدلال عمومی و هوش انتزاعی (ARC-AGI)
هوش مصنوعی GPT 5.2 در ارزیابیهای مرتبط با استدلال عمومی و هوش انتزاعی، جهشی کمسابقه را ثبت کرده است. بنچمارکهای ARC-AGI بهطور خاص برای سنجش توانایی «تفکر عمومی و حل مسائل جدید» طراحی شدهاند؛ یعنی مسائلی که مدل نمیتواند صرفاً با حفظ الگو یا دانش قبلی آنها را حل کند.
عملکرد در ARC-AGI-1
در آزمون ARC-AGI-1 (Verified)، مدل GPT-5.2 Pro اولین مدلی است که موفق شده از مرز ۹۰٪ دقت عبور کند. این نتیجه نسبت به رکورد سال گذشته (۸۷٪) پیشرفت قابلتوجهی محسوب میشود و در عین حال، هزینه دستیابی به این سطح عملکرد حدود ۳۹۰ برابر کاهش یافته است؛ موضوعی بسیار مهم برای استفادههای عملی و مقیاسپذیر.
عملکرد در ARC-AGI-2
نسخه پیشرفتهتر این آزمون، یعنی ARC-AGI-2 (Verified)، سطح دشواری بالاتری دارد و تمرکز آن بر استدلال سیال (Fluid Reasoning) و حل مسائل کاملاً جدید و انتزاعی است. در این ارزیابی:
- GPT-5.2 Thinking با ثبت امتیاز ۵۲.۹٪ رکورد جدیدی در میان مدلهای دارای زنجیره استدلال (Chain-of-Thought) ثبت کرده است.
- GPT-5.2 Pro حتی عملکرد بالاتری داشته و به دقت ۵۴.۲٪ رسیده است
انواع مدل های GPT 5.2
استفاده از هوش مصنوعی GPT 5.2 در محیط ChatGPT، برای کاربران بهصورت روزمره کاملاً محسوستر و روانتر شده است. این مدل در مقایسه با نسلهای قبلی ساختارمندتر، قابلاعتمادتر و در عین حال خوشتعاملتر است و تجربه کاربری بهتری را در مکالمات روزانه ارائه میدهد.
GPT-5.2 Instant | سریع و کاربردی برای کارهای روزمره
GPT-5.2 Instant یک مدل سریع و توانمند برای استفادههای روزانه، یادگیری و کارهای عمومی است. این نسخه بهویژه در موارد زیر بهبود قابلتوجهی دارد:
- پاسخگویی به سؤالات اطلاعاتی (Info-seeking)
- آموزشهای مرحلهبهمرحله و راهنماها (How-to & Walk-throughs)
- نگارش فنی و ترجمه
- توضیحات شفافتر با ارائه نکات کلیدی در ابتدای پاسخ
این مدل بر پایه لحن مکالمهای گرم GPT-5.1 Instant توسعه یافته، اما خروجیها را واضحتر و هدفمندتر ارائه میکند.
GPT-5.2 Thinking | انتخاب حرفهای برای کارهای عمیق
GPT-5.2 Thinking برای انجام کارهای پیچیده و تحلیلی طراحی شده است. این مدل در سناریوهایی که نیاز به دقت، عمق و ساختار دارند، عملکرد بسیار بهتری دارد، از جمله:
- برنامهنویسی و حل مسائل فنی
- خلاصهسازی و تحلیل اسناد طولانی
- پاسخگویی به سؤالات درباره فایلهای آپلودشده
- حل مسائل ریاضی و منطقی بهصورت مرحلهبهمرحله
- کمک به برنامهریزی و تصمیمگیری با جزئیات کاربردی و ساختار شفاف
این نسخه برای کاربرانی مناسب است که میخواهند خروجی حرفهایتر و پولیششدهتر دریافت کنند.
GPT-5.2 Pro | دقیقترین انتخاب برای سؤالات سخت
GPT-5.2 Pro هوشمندترین و قابلاعتمادترین گزینه برای سؤالات دشوار و حساس است؛ جایی که کیفیت پاسخ از سرعت مهمتر است. تستهای اولیه نشان میدهد که این مدل:
- خطاهای اساسی کمتری دارد
- در حوزههای پیچیده مانند برنامهنویسی عملکرد قویتری ارائه میدهد
- برای تحلیلهای مهم و تصمیمهای حیاتی گزینهای مطمئنتر است
ایمنی (Safety) در GPT 5.2
هوش مصنوعی GPT 5.2 بر پایه رویکرد «پاسخدهی ایمن» توسعه یافته و تلاش میکند در عین ارائه پاسخهای مفید، بهطور کامل به مرزهای ایمنی پایبند بماند. در این نسخه، واکنش مدل در مکالمات حساس مانند مسائل مرتبط با سلامت روان، خودآسیبرسانی و وابستگی عاطفی بهطور محسوسی بهبود یافته و میزان پاسخهای نامطلوب نسبت به نسلهای قبلی کاهش پیدا کرده است. همچنین OpenAI در حال راهاندازی تدریجی سیستم تشخیص سن برای اعمال محافظتهای محتوایی خودکار برای کاربران زیر ۱۸ سال است. در مجموع، GPT 5.2 نسبت به نسلهای قبل ایمنتر، مسئولانهتر و قابلاعتمادتر طراحی شده و همزمان توسعه آن برای بهبود تجربه کاربری و کاهش محدودیتهای غیرضروری ادامه دارد.
دسترسی و قیمتگذاری (Availability & Pricing) GPT 5.2
هوش مصنوعی GPT 5.2 از امروز بهصورت تدریجی در ChatGPT عرضه میشود و ابتدا در پلنهای پولی شامل Plus، Pro، Go، Business و Enterprise در دسترس قرار میگیرد. این انتشار بهصورت مرحلهای انجام میشود تا پایداری و کیفیت سرویس حفظ شود؛ بنابراین اگر بلافاصله مدل را مشاهده نکردید، لازم است کمی بعد دوباره بررسی کنید.
مدل GPT-5.1 نیز تا سه ماه برای کاربران پولی بهعنوان مدل قدیمی (Legacy) در دسترس خواهد بود و پس از آن از ChatGPT حذف میشود.
نامگذاری مدلها در ChatGPT و API
| ChatGPT | API |
|---|---|
| ChatGPT-5.2 Instant | gpt-5.2-chat-latest |
| ChatGPT-5.2 Thinking | gpt-5.2 |
| ChatGPT-5.2 Pro | gpt-5.2-pro |
در API:
- GPT-5.2 Thinking با نام
gpt-5.2 - GPT-5.2 Instant با نام
gpt-5.2-chat-latest - GPT-5.2 Pro با نام
gpt-5.2-pro
در دسترس هستند.
همچنین در GPT-5.2 Pro امکان تنظیم پارامتر reasoning فراهم شده و هر دو مدل Thinking و Pro از سطح جدید xhigh برای کارهایی که کیفیت در آنها اولویت دارد پشتیبانی میکنند.
قیمتگذاری API (بهازای هر یک میلیون توکن)
| مدل | ورودی | ورودی کششده | خروجی |
|---|---|---|---|
| gpt-5.2 / gpt-5.2-chat-latest | $1.75 | $0.175 | $14 |
| gpt-5.2-pro | $21 | – | $168 |
| gpt-5.1 / gpt-5.1-chat-latest | $1.25 | $0.125 | $10 |
| gpt-5-pro | $15 | – | $120 |
🔹 GPT-5.2 با وجود قیمت بالاتر نسبت به GPT-5.1، بهدلیل بهرهوری توکنی بالاتر، در بسیاری از سناریوهای حرفهای هزینه نهایی رسیدن به کیفیت مطلوب را کاهش میدهد.
🔹 تخفیف ۹۰٪ برای ورودیهای کششده نیز در دسترس است.
نکات مهم
- قیمت اشتراک ChatGPT تغییری نکرده است.
- در API فعلاً برنامهای برای حذف GPT-5.1، GPT-5 یا GPT-4.1 وجود ندارد و هرگونه تغییر با اطلاعرسانی قبلی انجام میشود.
- نسخهای از GPT-5.2 که بهطور خاص برای Codex بهینه شده باشد، در هفتههای آینده منتشر خواهد شد.
بهطور خلاصه، GPT 5.2 با وجود قدرت بالاتر، همچنان برای استفاده عمیق در پروژههای روزمره و کاربردهای سازمانی قابلدسترس و مقرونبهصرفه باقی مانده است.
برای کارهایی که نیاز دارند مدل فراتر از حداکثر طول کانتکست فکر کند، نسخهٔ GPT-5.2 Thinking با اندپوینت جدید Responses /compact سازگار است؛ اندپوینتی که باعث میشود مدل بتواند از یک پنجرهٔ کانتکست مؤثر بزرگتر استفاده کند.
به این ترتیب، GPT-5.2 Thinking میتواند جریانهای کاری طولانی و سنگین (بهخصوص کارهایی که ابزارهای مختلف در آن استفاده میشود) را بهتر مدیریت کند؛ کارهایی که در حالت عادی بهدلیل محدودیت طول کانتکست شدنی نبودند.
دانلود و نصب GPT 5.2
برای دانلود و نصب مدل gpt 5.2 با توجه به نسخه سیستم عامل خود میتوانید، از طریق وبسایت ChatGPT، اپلیکیشن رسمی در اندروید و iOS و همچنین از طریق API برای توسعهدهندگان در دسترس است. کاربران موبایل میتوانند با بهروزرسانی اپلیکیشن ChatGPT به آخرین نسخه، بهطور خودکار به GPT 5.2 دسترسی پیدا کنند.
